Obj #2 Minería de Datos
Minería de Datos

Introducción:
En el panorama actual, la minería de datos no solo es una herramienta; es un imperativo estratégico. Esta disciplina amalgama estadística, matemáticas y programación para desvelar los secretos ocultos en vastos conjuntos de datos. En este blog, nos adentraremos en sus matices y aplicaciones.
¿Que es la Minería de Datos?
Es una técnica asistida por computadora que se utiliza en los análisis para procesar y explorar grandes conjuntos de datos. Abarca una variedad de técnicas, desde la clásica exploración de datos hasta el aprendizaje profundo. Al utilizar algoritmos avanzados, como maquinas de soporte vectorial y redes neuronales, se busca no solo descubrir datos, sino predecir comportamientos futuros. La minería de datos transforma datos en bruto en conocimiento práctico. Las compañías utilizan dicho conocimiento para resolver problemas, analizar las consecuencias en el futuro de decisiones empresariales y aumentar sus márgenes de beneficio.Proceso de la Minería de Datos:
1. Recopilación de Datos:
Desde fuentes tradicionales hasta sensores IoT ("Internet of Things"), la diversidad en la adquisición de datos plantea desafíos y oportunidades. Métodos como scraping web y APIs(“interfaz de programación de aplicaciones”) son cruciales para recopilar datos heterogéneos.
2. Pre-procesamiento:
La calidad de los datos es esencial. Aquí, técnicas como la imputación de valores faltantes y la normalización desempeñan un papel crucial para garantizar que los datos estén listos para su análisis.
3. Exploración de Datos:
La exploración va más allá de gráficos y estadísticas descriptivas. Utilizando técnicas de visualización avanzadas y análisis de componentes principales, se busca comprender la complejidad intrínseca de los datos.

4. Modelado:
El surgimiento de modelos complejos, desde redes neuronales hasta algoritmos de agrupamiento jerárquico, permite la identificación de patrones sutiles y no lineales en los datos.
5. Evaluación:
La validación cruzada y las métricas específicas del dominio se utilizan para evaluar la robustez del modelo, evitando la sobreajustación y garantizando la aplicabilidad a situaciones del mundo real
6. Despliegue:
La implementación de modelos en entornos operativos implica la integración de sistemas, la monitorización continua y la retroalimentación constante para ajustes y mejoras.

Protocolo de un proyecto de Minería de datos
El éxito radica en una planificación meticulosa.
1- Definición del Problema:
Especificar claramente el problema o la pregunta que se busca resolver con la minería de datos.Establecer los objetivos del proyecto de manera precisa y cuantificable.
2- Entendimiento del Negocio:
Colaborar con los expertos en el dominio para comprender la naturaleza del negocio y sus necesidades.
Identificar las variables clave que afectan al problema y las métricas de rendimiento relevantes.
3- Exploración de Datos:
Recolectar datos relevantes para el problema.
Realizar un análisis exploratorio para comprender la estructura y características básicas de los datos.
4- Preparación de Datos:
Limpiar y pre-procesar los datos para eliminar ruido y redundancias.
Transformar variables según sea necesario.
Dividir los datos en conjuntos de entrenamiento y prueba.

5- Selección de Modelos y Algoritmos:
Seleccionar los algoritmos de minería de datos más apropiados según los objetivos del proyecto.
Configurar los parámetros de los modelos.
6- Entrenamiento del Modelo:
Utilizar el conjunto de entrenamiento para entrenar los modelos seleccionados.
Ajustar los modelos según sea necesario.
7- Validación del Modelo:
Evaluar el rendimiento del modelo utilizando el conjunto de prueba.
Ajustar los modelos según los resultados de la validación.
8- Interpretación de Resultados:
Interpretar los resultados del modelo en términos del problema de negocio.
Identificar patrones, tendencias y relaciones significativas.
9- Despliegue:
Implementar el modelo en un entorno de producción.
Integrar el modelo en los procesos empresariales existentes.
10- Evaluación Continua:
Monitorear el rendimiento del modelo en el entorno de producción.
Realizar ajustes y mejoras según sea necesario.

11- Documentación:
Documentar el proceso completo, incluidos los pasos seguidos, decisiones tomadas y resultados obtenidos.
Proporcionar informes y visualizaciones claras.
12- Comunicación de Resultados:
Presentar los hallazgos y recomendaciones a las partes interesadas.
Proporcionar información útil para la toma de decisiones.
Este protocolo general proporciona un marco para guiar el desarrollo de proyectos de minería de datos, pero ten en cuenta que la flexibilidad y adaptabilidad son esenciales, ya que cada proyecto puede tener requisitos específicos.

Técnicas en la Minería de Datos:
La minería de datos es un proceso que implica descubrir patrones, tendencias y conocimientos útiles a partir de conjuntos de datos grandes y complejos. Hay diversas técnicas y enfoques utilizados en la minería de datos para extraer información valiosa. Aquí tienes algunas técnicas comunes en la minería de datos:
1- Pre-procesamiento de Datos:
Limpieza de Datos: Eliminación de valores atípicos, manejo de datos faltantes y corrección de errores.
Transformación de Datos: Normalización, discretización y codificación de variables.

2- Exploración de Datos:
Estadísticas Descriptivas: Resúmenes estadísticos para comprender la distribución y la estructura de los datos.
Visualización de Datos: Gráficos y diagramas para identificar patrones visuales.

3- Selección de Características:
Análisis de Importancia: Identificación de las variables más relevantes para el análisis.
Reducción de Dimensionalidad: Técnicas como Análisis de Componentes Principales (PCA) para reducir la complejidad del conjunto de datos.

4- Modelado Predictivo:
Regresión: Predicción de valores numéricos.
Clasificación: Categorización de datos en clases predefinidas.
Aprendizaje no supervisado: Agrupamiento de datos sin etiquetas predefinidas (por ejemplo, k-medias).
Aprendizaje supervisado: Utilización de datos etiquetados para entrenar modelos predictivos.

5- Algoritmos de Minería de Datos:
Árboles de Decisión: Modelos basados en reglas de decisión.
Redes Neuronales: Modelos inspirados en la estructura del cerebro.
Máquinas de Soporte Vectorial (SVM): Útiles para problemas de clasificación y regresión.
Algoritmos de Agrupamiento: K-medias, jerárquico, etc.

6- Evaluación de Modelos:
Validación Cruzada: División del conjunto de datos en subconjuntos para evaluar la capacidad predictiva del modelo.
Matriz de Confusión: Evaluación de la precisión de un modelo de clasificación.

7- Reglas de Asociación:
Apriori: Identificación de relaciones y patrones frecuentes en conjuntos de datos.
8- Minería de Texto:
Análisis de Sentimientos: Extracción de emociones y opiniones de textos.
Extracción de Información: Identificación y clasificación de información relevante en textos.

9- Minería de Secuencias y Series Temporales:
Análisis de Secuencias: Identificación de patrones en secuencias de datos.
Predicción Temporal: Pronóstico de valores en función del tiempo.
10- Privacidad y Ética:
Anonimización de Datos: Protección de la privacidad de los individuos en los conjuntos de datos.
Consideraciones Éticas: Reflexión sobre el uso responsable de la información extraída.
Estas son solo algunas de las técnicas utilizadas en la minería de datos, y la elección de la técnica adecuada dependerá del tipo de datos, el objetivo del análisis y otros factores específicos del problema.

Ejemplos de uso de la Minería de Datos:
1- Negocios:
Segmentación de Clientes: Utilizar la minería de datos para identificar grupos de clientes con comportamientos similares, lo que ayuda a personalizar estrategias de marketing.
Previsión de Ventas: Analizar patrones históricos de ventas para prever la demanda futura y ajustar el inventario en consecuencia.

2- Análisis de la Cesta de Compra:
Recomendación de Productos: Utilizar algoritmos de recomendación basados en patrones de compra para sugerir productos relacionados a los clientes.

3- Patrones de Fuga (Churn):
Retención de Clientes: Identificar patrones de comportamiento que sugieran que un cliente está en riesgo de abandonar un servicio o producto, permitiendo estrategias de retención.

Ejemplo: Una empresa de telecomunicaciones utiliza la minería de datos para identificar patrones de comportamiento que indican la probabilidad de que un cliente abandone sus servicios. Esto permite implementar estrategias de retención, como ofertas personalizadas.
4- Fraudes:
Detección de Fraudes Financieros: Analizar patrones de transacciones para identificar comportamientos anómalos y detectar posibles fraudes en tarjetas de crédito u operaciones financieras.

Ejemplo: Instituciones financieras utilizan algoritmos de minería de datos para analizar patrones de transacciones y detectar actividades sospechosas, como el uso no autorizado de tarjetas de crédito o fraudes bancarios
Ejemplo: Instituciones financieras utilizan algoritmos de minería de datos para analizar patrones de transacciones y detectar actividades sospechosas, como el uso no autorizado de tarjetas de crédito o fraudes bancarios
5- Recursos Humanos:
Selección de Personal: Utilizar análisis de datos para identificar características comunes en empleados exitosos y mejorar el proceso de contratación.
Gestión del Rendimiento: Evaluar el desempeño de los empleados mediante el análisis de datos para identificar áreas de mejora.

Ejemplo: Empresas utilizan la minería de datos en sus procesos de contratación, analizando datos de candidatos para identificar patrones relacionados con el éxito en roles específicos y mejorar la toma de decisiones de contratación.
6- Comportamiento en Internet:
Análisis de Clickstream: Analizar el comportamiento de navegación en sitios web para entender las preferencias de los usuarios y mejorar la experiencia en línea.

Ejemplo: Empresas de comercio electrónico analizan datos de clickstream para comprender cómo los usuarios interactúan con sus sitios web, mejorando la usabilidad y personalizando la experiencia de navegación.
7- Terrorismo:
Detección de Patrones Sospechosos: Analizar datos relacionados con actividades financieras, comunicaciones y movimientos para identificar patrones que puedan indicar actividades terroristas.

Ejemplo: Agencias de inteligencia utilizan la minería de datos para analizar patrones en comunicaciones, movimientos y actividades financieras con el objetivo de identificar posibles amenazas terroristas.
8- Juegos y Videojuegos:
Personalización de Experiencia: Utilizar datos de juego para personalizar la experiencia del jugador, adaptando niveles de dificultad, sugerencias y recompensas.
Detección de Trampas: Identificar patrones de juego sospechosos que podrían indicar trampas o comportamientos fraudulentos en línea.

Ejemplo: Plataformas de juegos en línea utilizan la minería de datos para analizar el comportamiento de los jugadores y adaptar la dificultad del juego, ofrecer recomendaciones personalizadas y ajustar las características del juego.
9- Ciencia e Ingeniería:
Descubrimiento de Nuevos Materiales: Utilizar técnicas de minería de datos para analizar propiedades de materiales y acelerar la investigación en ciencia de materiales.
Análisis de Experimentos: Evaluar grandes conjuntos de datos experimentales para descubrir patrones y relaciones entre variables.

Ejemplo: Investigadores en ciencia de materiales aplican técnicas de minería de datos para analizar grandes conjuntos de datos experimentales y descubrir patrones que ayudan en la identificación de nuevos materiales con propiedades específicas.
10- Genética:
Asociación Genética: Identificar patrones en datos genéticos para entender la relación entre genes y enfermedades.
Ejemplo: Investigadores en genética utilizan la minería de datos para analizar grandes conjuntos de datos genéticos e identificar asociaciones entre ciertos genes y enfermedades, lo que puede contribuir a la investigación médica.
Ejemplo: Investigadores en genética utilizan la minería de datos para analizar grandes conjuntos de datos genéticos e identificar asociaciones entre ciertos genes y enfermedades, lo que puede contribuir a la investigación médica.
11- Ingeniería Eléctrica:
Mantenimiento Predictivo: Analizar datos de sensores para predecir fallos en equipos eléctricos antes de que ocurran, permitiendo un mantenimiento preventivo.
12- Análisis de Gases:
Calidad del Aire:Utilizar datos de sensores para monitorear la calidad del aire y identificar patrones que puedan indicar niveles peligrosos de contaminantes.

Estos son solo algunos ejemplos, la minería de datos se puede aplicar en una amplia variedad de campos para obtener información valiosa y tomar decisiones informadas. Cada aplicación requiere un enfoque específico y adaptado a los datos y objetivos particulares.
Estos son solo algunos ejemplos, la minería de datos se puede aplicar en una amplia variedad de campos para obtener información valiosa y tomar decisiones informadas. Cada aplicación requiere un enfoque específico y adaptado a los datos y objetivos particulares.

Minería de datos y otras disciplinas análogas de la estadística y la informática:
La minería de datos se entrelaza con varias disciplinas relacionadas, cada una contribuyendo con enfoques y técnicas específicas para el análisis de datos. A continuación, se describen algunas disciplinas análogas a la minería de datos:
1- Aprendizaje Automático (Machine Learning):
Definición: El aprendizaje automático es una rama de la inteligencia artificial que se centra en desarrollar algoritmos y modelos que permiten a las máquinas aprender patrones a partir de datos.Relación: La minería de datos a menudo utiliza técnicas de aprendizaje automático para construir modelos predictivos y descriptivos a partir de los datos. Ambas disciplinas comparten el objetivo de extraer conocimiento de los datos.
2- Inteligencia Artificial (IA):
Definición: La inteligencia artificial es un campo más amplio que busca crear sistemas capaces de realizar tareas que normalmente requieren inteligencia humana, como el aprendizaje, la percepción, el razonamiento y la toma de decisiones.Relación: La minería de datos es una aplicación específica de la inteligencia artificial, centrándose en la extracción de conocimiento a partir de datos estructurados o no estructurados mediante técnicas analíticas.
3- Análisis de Datos (Data Analytics):
Definición: El análisis de datos implica la inspección, limpieza y modelado de datos para descubrir información útil, llegar a conclusiones y respaldar la toma de decisiones.Relación: La minería de datos se considera una forma de análisis de datos avanzado, ya que utiliza técnicas específicas para descubrir patrones y relaciones en conjuntos de datos grandes.
4- Estadística:
Definición: La estadística es la disciplina que se ocupa de la recopilación, análisis, interpretación, presentación y organización de datos.
Relación: La minería de datos incorpora métodos estadísticos para la inferencia y la validación de modelos. Los principios estadísticos son fundamentales para comprender la significancia de los resultados obtenidos.
5- Big Data:
Definición: Big Data se refiere al manejo y análisis de conjuntos de datos extremadamente grandes y complejos que superan la capacidad de las herramientas de procesamiento de datos convencionales.Relación: La minería de datos a menudo se realiza en el contexto de Big Data, donde las técnicas y herramientas específicas se utilizan para extraer información valiosa de grandes volúmenes de datos.
Relación: La minería de datos es una subdisciplina de la ciencia de datos, contribuyendo con enfoques específicos para la extracción de patrones y conocimientos.
6- Ciencia de Datos:
Definición: La ciencia de datos es un campo interdisciplinario que combina métodos, procesos y sistemas para extraer conocimiento y perspicacia de datos en diversas formas.Relación: La minería de datos es una subdisciplina de la ciencia de datos, contribuyendo con enfoques específicos para la extracción de patrones y conocimientos.
Estas disciplinas comparten objetivos y métodos, pero cada una tiene un enfoque particular. La minería de datos se destaca por su enfoque en la exploración y descubrimiento de patrones en los datos, utilizando técnicas avanzadas de análisis.






La aplicación de la teoría de la información en la minería de datos proporciona herramientas y conceptos valiosos para medir la complejidad y la estructura de los datos, así como para optimizar la representación y la interpretación de la información contenida en conjuntos de datos grandes y complejos.

Minería de datos basada en la teoría de la información:
La minería de datos basada en la teoría de la información se enfoca en el uso de conceptos y métricas provenientes de la teoría de la información para analizar y extraer patrones significativos de conjuntos de datos. La teoría de la información, desarrollada por Claude Shannon, se centra en la cuantificación de la información y la medida de la incertidumbre en un sistema. Aquí hay algunos aspectos clave de cómo la teoría de la información se aplica en la minería de datos:
1. Entropía:
La entropía es una medida de la incertidumbre o desorden en un conjunto de datos. En minería de datos, la entropía se puede utilizar para evaluar la homogeneidad de un conjunto de datos. La reducción de la entropía indica una mayor organización o patrón en los datos.2. Ganancia de Información:
La ganancia de información se utiliza en algoritmos de aprendizaje automático, como los árboles de decisión, para evaluar la importancia de un atributo en la clasificación de datos. Se calcula comparando la entropía antes y después de dividir los datos según un atributo.3. Teorema de Codificación de Fuente:
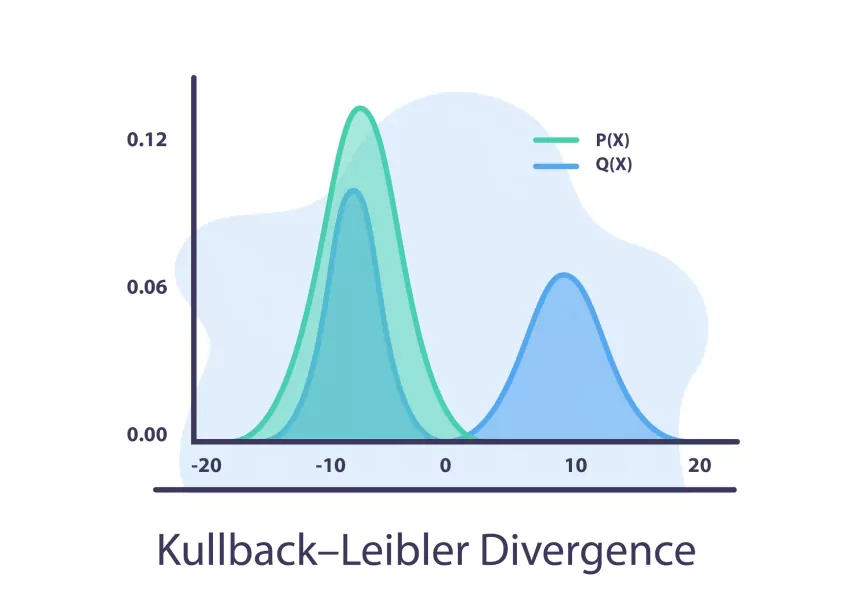
La teoría de la información también se aplica en la compresión de datos. Algoritmos de compresión, como el algoritmo de Huffman, se basan en la teoría de la información para representar los datos de manera eficiente, eliminando redundancias.4. Divergencia y Distancia de Kullback-Leibler:
La divergencia de Kullback-Leibler mide la diferencia entre dos distribuciones de probabilidad. Se utiliza en minería de datos para comparar distribuciones y evaluar la similitud o diferencia entre conjuntos de datos.5. Entropía Cruzada:
En el contexto del aprendizaje automático, la entropía cruzada se utiliza como una función de pérdida para medir la discrepancia entre la distribución de probabilidad predicha por un modelo y la distribución de probabilidad real de los datos.6. Reducción de Dimensión:
Técnicas de reducción de dimensión, como el análisis de componentes principales (PCA), se pueden vincular a la teoría de la información al intentar representar los datos en términos de las variables más informativas.7. Análisis de Información Mutua:
La información mutua mide la dependencia entre dos variables y se utiliza para evaluar la relevancia de una variable en relación con otra. En minería de datos, esto puede ayudar a identificar la importancia de ciertos atributos en la predicción o clasificación de datos.La aplicación de la teoría de la información en la minería de datos proporciona herramientas y conceptos valiosos para medir la complejidad y la estructura de los datos, así como para optimizar la representación y la interpretación de la información contenida en conjuntos de datos grandes y complejos.
Tendencias en la Minería de Datos
Las tendencias en minería de datos están en constante evolución, impulsadas por avances tecnológicos, cambios en la forma en que se generan y utilizan los datos, y las demandas cambiantes de la sociedad y la industria. Aquí hay algunas tendencias notables en minería de datos:
1. Aprendizaje Automático Explicativo (Explainable Machine Learning):
A medida que los modelos de aprendizaje automático se vuelven más complejos, hay una creciente demanda de comprensibilidad y explicabilidad. La capacidad de explicar cómo y por qué un modelo toma decisiones es esencial, especialmente en áreas críticas como la atención médica y las finanzas.

2. Énfasis en la Ética y la Privacidad:
Con la creciente conciencia sobre los problemas éticos y de privacidad asociados con el uso de datos, se espera que las organizaciones enfoquen más en prácticas éticas de minería de datos y en la implementación de medidas para proteger la privacidad de los individuos.
3. Automatización de Procesos de Minería de Datos (AutoML):
Las herramientas de AutoML están en aumento, permitiendo a las organizaciones automatizar partes del proceso de minería de datos, desde la preparación de datos hasta la selección y ajuste de modelos. Esto facilita el acceso a la minería de datos incluso para aquellos sin experiencia técnica profunda.

4. Minería de Datos en Tiempo Real:
La capacidad de analizar datos en tiempo real se vuelve esencial en industrias como las finanzas, la salud y el comercio electrónico. La minería de datos en tiempo real permite tomar decisiones más rápidas y reactivas basadas en la información más reciente.

5. Fusionar Inteligencia Artificial y Minería de Datos:
La convergencia de la inteligencia artificial (IA) y la minería de datos sigue siendo una tendencia clave. La IA se utiliza para mejorar algoritmos de minería de datos y crear sistemas más avanzados y adaptables.
6. Minería de Datos Federada:
Con un enfoque en la privacidad y la seguridad de los datos, la minería de datos federada permite el análisis de datos distribuidos sin centralizar la información. Esto es especialmente útil en entornos donde los datos no pueden o no deben ser compartidos centralmente.
7. Aplicaciones en Edge Computing:
La capacidad de realizar análisis de datos directamente en el borde de la red (edge computing) se vuelve más importante, especialmente en entornos donde la latencia y el ancho de banda son críticos.

8. Minería de Datos con Grafos:
El análisis de datos basado en grafos es una tendencia en crecimiento. Esto implica modelar relaciones complejas entre entidades mediante el uso de grafos, lo que es particularmente útil en la detección de fraudes, análisis de redes sociales y otras aplicaciones.
9. Interoperabilidad de Herramientas y Plataformas:
Existe una creciente necesidad de que las herramientas y plataformas de minería de datos sean interoperables, permitiendo la integración fluida con otras herramientas y sistemas dentro de las organizaciones.
10. Minería de Datos en Ciencias de la Salud:
La minería de datos desempeña un papel crucial en la investigación médica y la toma de decisiones clínicas. Se espera que esta tendencia continúe con el uso de datos masivos en el campo de la salud.

Estas tendencias reflejan la evolución constante de la minería de datos para adaptarse a las demandas cambiantes y aprovechar las oportunidades emergentes en el ámbito de la analítica de datos.

Dizz.


Comentarios
Publicar un comentario